Executive Summary
Objective: The SAT Tech IoT Data Lake Platform is a scalable, secure, and efficient solution designed to manage IoT device data. Built on AWS, it supports real-time ingestion, enrichment, storage, advanced analytics, and monetisation while ensuring privacy compliance and robust security.
Key Features:
- Data Management: Real-time ingestion, schema normalisation, and curation for downstream analytics.
- Advanced Analytics: Supports behavioural insights through machine learning (AWS SageMaker).
- Monetisation Models: Flexible options, including subscription tiers, pay-per-use, and custom solutions.
- Scalability: Modular architecture to support growing data volumes and new use cases.
- Compliance: GDPR-ready workflows with anonymisation and strong data governance.
Implementation Plan:
- Deliver an MVP within 6–9 months, focusing on core features:
- Data ingestion and enrichment pipelines.
- Anonymised data access via APIs.
- Subscription-based monetisation.
- Incrementally expand capabilities with behavioural analytics and advanced governance.
Projected Benefits:
- Healthcare: Improved patient monitoring and reduced risks through motion analytics.
- Smart Buildings: Optimised energy and space utilisation.
- Retail: Enhanced consumer insights and in-store experience.
Risks and Mitigation:
- Technical Risks: Overload or latency mitigated through scalable AWS services like Kinesis and SageMaker.
- Operational Risks: Addressed via training, Agile delivery, and phased deployment.
- Business Risks: Minimized through targeted early customer acquisition and adaptive pricing models.
Roadmap Highlights:
- Year 1: MVP deployment and healthcare focus.
- Year 2: AI/ML integration for behavioural insights.
- Year 3: Global scalability and diverse customer base.
Call to Action: Approve the MVP implementation to unlock immediate value, enabling early revenue generation and establishing SAT Tech as a leader in IoT data solutions.
High-Level Architecture Overview
The proposed architecture is modular and divided into the following core layers:
- Data Ingestion Layer: Manages the collection of raw data from IoT devices in real time.
- Data Enrichment & Normalisation Layer: Processes and unifies raw data into a consistent schema.
- Data Lake Storage: A scalable repository for raw, enriched, and curated data.
- Data Processing Layer: Supports transformations, analytics, and machine learning.
- Anonymisation & Governance Layer: Ensures privacy and compliance.
- Data Consumption Layer: Facilitates access to data through APIs or data exchange platforms.
- Security, Compliance, and Monitoring: Protects data, enforces governance, and provides visibility into operations.
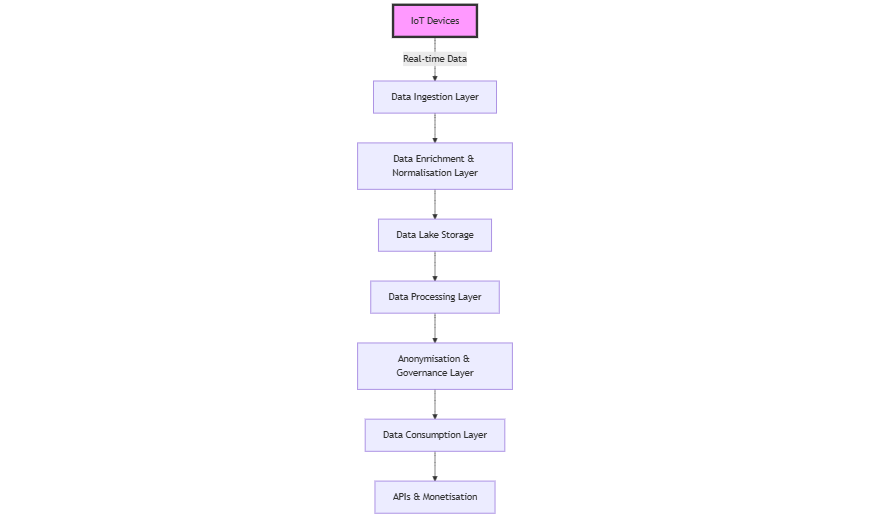
Detailed Design
1. Data Ingestion Layer
Purpose:
To ingest data from diverse IoT devices and vendors in real time, ensuring high throughput and reliability.
AWS Services:
- AWS IoT Core: Manages IoT device connectivity, processes incoming data streams, and routes them downstream.
- AWS Kinesis Data Streams: Buffers and ingests large-scale streaming data, ensuring resilience and scalability.
- AWS Lambda: Pre-processes data, adding metadata (e.g., timestamps, device IDs), and directs it to the appropriate processing layer.
Key Features:
- Real-time ingestion of motion data from devices.
- Resilience to high-volume traffic spikes using Kinesis.
- Pre-processing workflows for metadata enrichment.
MVP Implementation:
Focus on AWS IoT Core and Kinesis for ingestion. Use Lambda for lightweight processing.
2. Data Enrichment & Normalisation Layer
Purpose:
To transform raw IoT data into a unified, enriched schema for downstream analysis.
AWS Services:
- AWS Lambda: Executes lightweight transformations and enrichments in real time.
- AWS Glue: Handles complex Extract, Transform, Load (ETL) workflows for large datasets.
- DynamoDB (Optional): Stores metadata for quick lookups (e.g., device configurations).
- AWS Step Functions: Orchestrates data processing workflows.
Key Features:
- Metadata enrichment (e.g., location, device type).
- Schema unification across diverse IoT vendors.
- Automation of data pipelines using Glue and Step Functions.
MVP Implementation:
Start with Lambda for basic enrichment tasks and scale to Glue for larger ETL workflows once data volume increases.
3. Data Lake Storage
Purpose:
To store data in raw, enriched, and curated forms for future analytics and external consumption.
AWS Services:
- Amazon S3: Serves as the backbone for data lake storage.
- AWS Lake Formation: Manages data access controls and governance.
Bucket Structure:
- Raw Data: Unprocessed data as ingested from devices.
- Enriched Data: Normalised and processed data with added context.
- Curated Data: Final datasets ready for analysis or sharing.
Key Features:
- Scalability to handle growing data volumes.
- Fine-grained access control using Lake Formation.
MVP Implementation:
Focus on Amazon S3 for storage. Introduce Lake Formation as governance requirements grow.
4. Data Processing Layer
Purpose:
To enable transformations, analytics, and advanced machine learning.
AWS Services:
- Amazon SageMaker: Builds, trains, and deploys machine learning models for behavioural analysis.
- AWS Glue or EMR: Supports distributed data processing using Spark or Hadoop.
- AWS Lambda: Handles lightweight processing tasks.
- Redshift Spectrum: Runs SQL queries directly on S3-stored data.
Key Features:
- Behavioural analytics models for trend analysis (e.g., mobility patterns).
- Distributed processing for large-scale transformations.
- On-demand SQL queries on S3 data without additional ETL.
MVP Implementation:
Begin with SageMaker for model development and Glue for essential data transformations.
5. Anonymisation & Governance Layer
Purpose:
To enforce data privacy and ensure compliance with regulations like GDPR.
AWS Services:
- AWS Macie: Detects and protects sensitive data.
- Glue DataBrew: Automates data cleaning and anonymisation.
- IAM Policies: Manages access to sensitive data.
Key Features:
- Automated detection of personally identifiable information (PII).
- Data anonymisation workflows for external sharing.
- Strict access control with Identity and Access Management (IAM).
MVP Implementation:
Focus on Macie for detecting sensitive data and IAM for enforcing access policies.
6. Data Consumption Layer
Purpose:
To provide curated and anonymised data to internal stakeholders or third parties.
AWS Services:
- API Gateway: Offers RESTful APIs for accessing data.
- AWS Data Exchange: Monetises datasets by leasing them to external customers.
- Amazon Athena: Enables querying of curated data.
Key Features:
- APIs for real-time or batch data access.
- Subscription-based data leasing through AWS Data Exchange.
- Self-service querying for internal analysts using Athena.
MVP Implementation:
Start with API Gateway for data sharing. Introduce Athena for internal users and Data Exchange for monetisation in later phases.
7. Security, Compliance, and Monitoring
Purpose:
To safeguard data, ensure compliance, and provide visibility into platform operations.
AWS Services:
- AWS KMS (Key Management Service): Encrypts data in transit and at rest.
- AWS CloudTrail: Logs all API activity for auditing.
- AWS CloudWatch: Monitors platform health and performance.
- AWS Shield: Protects APIs against DDoS attacks.
Key Features:
- Encryption for sensitive data.
- Full audit trails for compliance.
- Real-time monitoring and alerts.
MVP Implementation:
Prioritise KMS for encryption and CloudTrail for auditing from the start.
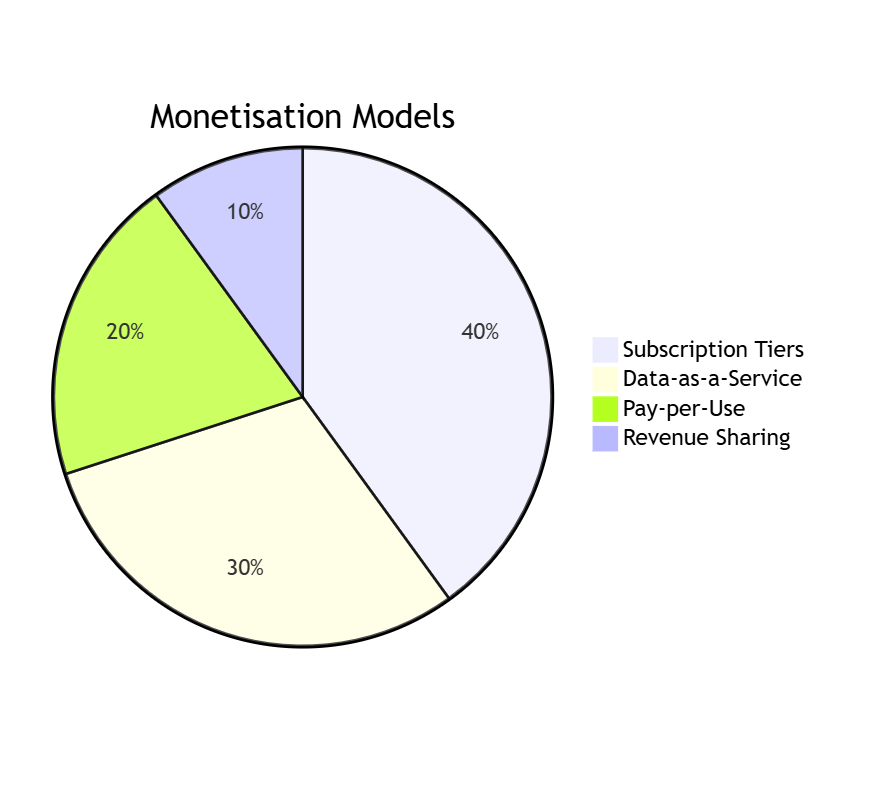
Monetisation Strategies
Key Models:
- Subscription Tiers:
- Basic: Historical aggregated data (£500/month).
- Premium: Real-time streams and behavioural insights (£2,000/month).
- Enterprise: Custom data solutions with SLA (£10,000/month).
- Pay-per-Use:
- Example: £0.10 per API call or £50 per GB of data streamed.
- Data-as-a-Service (DaaS):
- Example: Annual contracts (£100,000/year) for anonymised datasets.
- Revenue Sharing:
- Share a percentage of revenue generated from your data (e.g., 5%).
Implementation Plan
Estimated Timeline: 6–9 months
- Planning & Architecture Design: 3–4 weeks
- Infrastructure Setup: 4–6 weeks
- Data Pipeline Development: 6–8 weeks
- Machine Learning Model Development: 8–12 weeks
- UI/UX Development: 8–10 weeks
- Testing & QA: 3–4 weeks
- Deployment & Rollout: 2–3 weeks
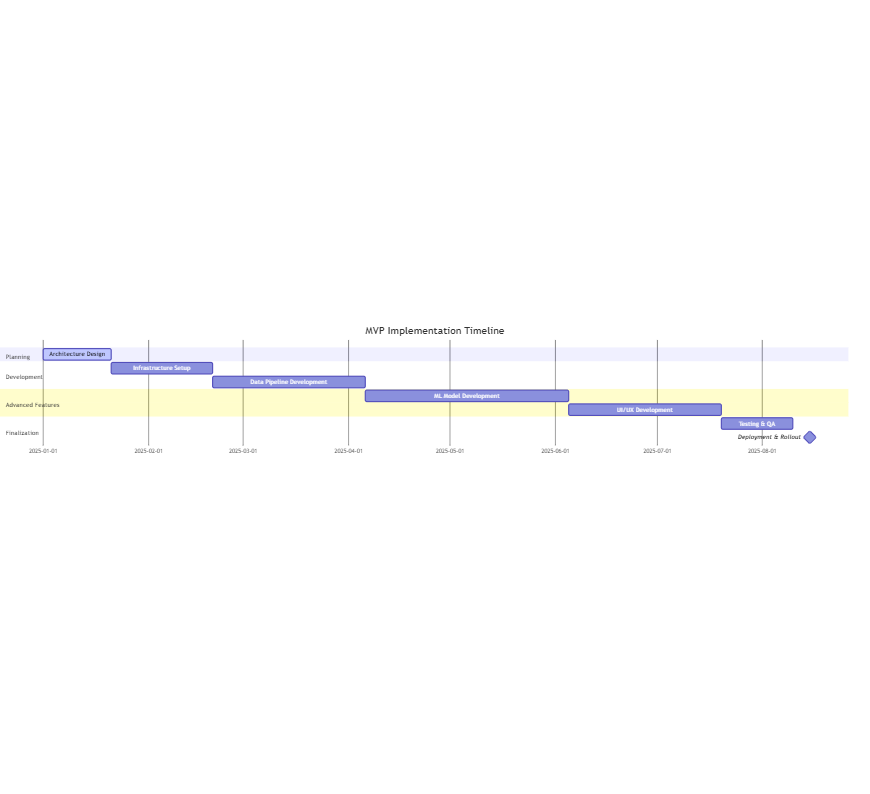
Team Structure
Minimum Viable Team (6 People):
- Cloud Architect/DevOps Engineer: Leads AWS infrastructure and DevOps pipelines.
- Data Engineer: Builds ETL pipelines and ensures data quality.
- Data Scientist: Develops and trains machine learning models.
- Full-Stack Developer: Designs the user interface and API.
- Business Development Manager: Handles customer acquisition and monetisation.
- Data Privacy Officer: Ensures compliance with GDPR and other regulations (part-time).
This detailed architecture and implementation plan outline a robust and scalable platform that aligns technical capabilities with business objectives, ensuring successful integration and monetisation of IoT data.
Potential Customers and Use Cases
The platform’s anonymised motion data and behavioural insights hold significant value across multiple industries. Below are the key customer segments, their use cases, and tailored monetisation strategies.
1. Healthcare and Wellness
Overview:
Healthcare providers can use motion data to monitor mobility trends, recovery patterns, and potential health risks, enhancing both preventative and reactive care.
Use Cases:
- Elderly Care: Monitor daily activity to detect anomalies like falls or inactivity, which may signal depression or mobility issues.
- Post-Surgery Recovery: Track mobility improvements after surgery and identify deviations from recovery plans.
- Preventative Care: Use motion data to build wellness programs for patients with chronic conditions like diabetes or arthritis.
- Home-Based Care: Enable remote monitoring of patients to alert caregivers to changes in physical activity or health status.
Potential Customers:
- Hospitals and clinics.
- Home healthcare providers.
- Insurance companies seeking risk assessments.
- Fitness and wellness companies.
Monetisation Strategy:
- Subscription Tiers: Real-time data for immediate interventions or aggregated trends for research purposes.
- Custom Data Solutions: Tailored datasets for specific demographics or regions.
2. Behavioural Science
Overview:
Researchers can use motion data to study human behaviour, cognitive patterns, and societal trends.
Use Cases:
- Cognitive Decline Studies: Detect early signs of conditions like Alzheimer’s or dementia through changes in movement patterns.
- Mental Health Research: Correlate motion patterns with mood disorders like depression or anxiety.
- Public Health Campaigns: Assess the impact of behavioural interventions (e.g., campaigns promoting physical activity).
- Urban Planning: Design walkable communities and optimise public spaces based on movement patterns.
Potential Customers:
- Universities and research institutions.
- Public health organisations.
- Urban planning firms.
Monetisation Strategy:
- Data-as-a-Service (DaaS): Access to anonymised datasets for research.
- Collaborative Partnerships: Licensing data for specific studies or initiatives.
3. Pharmaceuticals
Overview:
Motion data can support drug development, clinical trials, and patient adherence monitoring, enabling data-driven insights into treatment efficacy.
Use Cases:
- Drug Efficacy Trials: Assess how treatments for mobility disorders (e.g., Parkinson’s, arthritis) improve physical activity.
- Clinical Trials: Use motion data as a quantifiable metric for trial outcomes.
- Adherence Monitoring: Track activity levels to ensure patients are following prescribed regimens.
Potential Customers:
- Pharmaceutical companies.
- Clinical research organisations (CROs).
- Biotechnology firms.
Monetisation Strategy:
- Per-Study Pricing: Provide datasets tailored to trial needs.
- Subscription Models: Offer ongoing access for post-market surveillance.
4. Smart Building Management
Overview:
Building managers and urban planners can use motion data to optimise energy usage, security, and space utilisation.
Use Cases:
- Energy Optimisation: Adjust heating and lighting based on occupancy patterns.
- Space Utilisation: Identify high-traffic areas for better space planning.
- Security Enhancements: Detect unusual activity patterns to prevent breaches.
Potential Customers:
- Real estate firms.
- Property management companies.
- Smart city initiatives.
Monetisation Strategy:
- Real-Time Data Leases: Provide APIs for immediate insights.
- Bulk Data Sales: Historical data for planning purposes.
5. Retail and Marketing
Overview:
Retailers can analyse motion data to optimise store layouts, understand foot traffic patterns, and enhance customer engagement.
Use Cases:
- Store Layout Optimisation: Place high-value items in areas with the most foot traffic.
- Targeted Marketing: Use movement trends to deliver personalised offers or adjust campaigns.
- Mall Management: Analyse foot traffic to determine optimal leasing rates for store spaces.
Potential Customers:
- Retail chains.
- Shopping mall operators.
- Marketing agencies.
Monetisation Strategy:
- API Access: Pay-per-use APIs for real-time traffic data.
- Subscription Tiers: Aggregated insights for strategic planning.
Charging Model Summary
Comparison of Monetisation Strategies
| Model | Description | Advantages | Disadvantages | Example |
|---|---|---|---|---|
| Subscription | Tiered pricing for access to data streams or insights. | Predictable revenue; easy scalability. | Requires differentiation between tiers. | £2,000/month for real-time data streams. |
| Pay-per-Use | Customers pay based on API calls or data volume. | Flexible; attracts smaller customers. | Revenue may vary with usage patterns. | £0.10 per 1,000 API calls. |
| Data-as-a-Service | Licensing large datasets for research or analytics. | High revenue potential for bulk sales. | Requires secure storage and transfer setup. | £100,000/year for pharmaceutical datasets. |
| Revenue Sharing | Share in revenue generated by customers using your data. | Potentially high returns from successful clients. | Unpredictable revenue stream. | 5% of revenue from data-driven products. |
Data Lifecycle Management
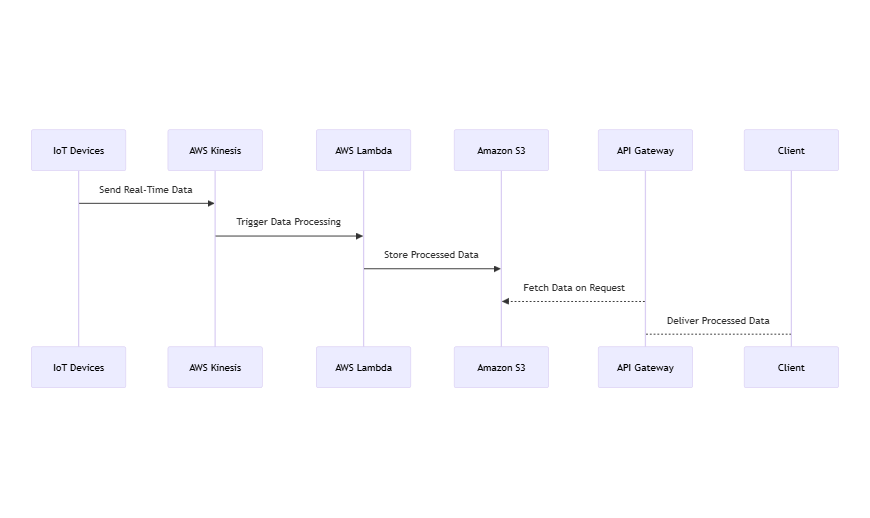
- Ingestion: IoT devices stream data into the platform via AWS IoT Core and Kinesis.
- Processing: Data flows through Lambda, Glue, and SageMaker for enrichment and analysis.
- Storage: Organised into raw, enriched, and curated layers within S3 buckets.
- Anonymisation: PII is automatically detected and masked using Macie and Glue DataBrew.
- Access: Curated data is made available via APIs, Athena, or AWS Data Exchange.
- Archival: Older datasets are moved to low-cost storage tiers (e.g., S3 Glacier) after 12 months.
- Purge: Data is deleted according to retention policies, ensuring compliance with GDPR.
Implementation Details and Key Considerations
To ensure the success of the SAT Tech platform, it’s important to address specific implementation considerations, trade-offs, and future scalability needs. Below is a more detailed breakdown of key aspects that complement the architecture and roadmap.
1. Prioritisation for the MVP
While the complete architecture is designed for scalability and advanced functionality, the MVP should focus on delivering a lean version that proves the platform’s value quickly. This approach reduces costs, shortens timelines, and enables early feedback for improvement.
MVP Priorities:
- Core Features:
- Real-time data ingestion using AWS IoT Core and Kinesis.
- Basic enrichment pipelines using Lambda and schema standardisation for IoT data.
- Data storage with S3, organised into raw and processed layers.
- Simple anonymisation workflows using Macie.
- Basic API-based data access through API Gateway.
- Exclusions for MVP:
- Advanced analytics or behavioural modelling (SageMaker deferred).
- Distributed data processing (Glue or EMR can be introduced later).
- Complex monetisation mechanisms (focus on subscription tiers first).
- Full governance features (Lake Formation and DataBrew deferred).
Outcome of MVP:
- A working platform capable of ingesting, processing, storing, and sharing data.
- Demonstrates value to early customers, particularly in key verticals like healthcare.
2. Security and Compliance Deep Dive
Given the sensitivity of IoT motion data and potential regulatory requirements, the platform must prioritise security and compliance from the outset.
Key Security Measures:
- Encryption:
- Data is encrypted at rest and in transit using AWS Key Management Service (KMS).
- Enable automatic encryption for S3 buckets and IoT Core data streams.
- Access Control:
- IAM policies ensure least-privilege access to resources.
- Role-based access control (RBAC) for internal and external users.
- Threat Detection:
- Enable Amazon GuardDuty for continuous monitoring of malicious activity.
- Use AWS Shield to protect APIs and endpoints from DDoS attacks.
- Auditing and Monitoring:
- CloudTrail logs all API activity for auditing.
- CloudWatch dashboards monitor pipeline health, latency, and usage patterns.
Compliance Workflow:
- Data Retention: Implement rules for data retention and deletion to comply with GDPR or HIPAA.
- PII Detection: Use Macie to flag and anonymise sensitive data fields.
- Third-Party Agreements: Draft data-sharing agreements with partners to ensure downstream compliance.
3. Data Pipeline Optimisation
The platform’s success depends on its ability to efficiently handle high-volume IoT data. Below are key optimisations for the ingestion and processing layers:
High-Throughput Ingestion:
- Use Kinesis Producer Library (KPL) to optimise batch writes from IoT devices.
- Partition Kinesis streams based on device IDs, regions, or other logical identifiers to prevent bottlenecks.
Data Enrichment at Scale:
- Use Lambda Reserved Concurrency to prevent overloading downstream services during spikes.
- For high-frequency pipelines, migrate enrichment tasks to Glue or EMR for parallel processing.
Cost Management:
- Use S3 lifecycle policies to transition older data to S3 Infrequent Access or Glacier.
- Use Spot Instances in EMR clusters to reduce costs for batch processing.
4. Advanced Analytics and AI/ML Models
Phase 2: Behavioural Insights
Once the MVP is validated, the platform can incorporate machine learning models to unlock deeper insights into IoT motion data.
- SageMaker Use Cases:
- Predictive trends (e.g., fall risks in elderly patients).
- Cluster analysis to segment user behaviour patterns.
- Real-time anomaly detection for high-priority alerts.
- Model Deployment:
- Use SageMaker Pipelines to automate training and deployment workflows.
- Integrate models into APIs for real-time predictions.
Optimisation:
- Pre-compute results for frequently requested insights to reduce API latency.
- Monitor model performance and accuracy using SageMaker’s built-in tools.
5. Monetisation and API Enhancements
As the platform scales, its monetisation mechanisms and APIs will need to evolve to support more customers and use cases.
Advanced API Features:
- Rate Limiting: Protect backend systems by enforcing API call limits.
- Dynamic Filtering: Allow users to query specific subsets of data using filtering parameters.
- API Analytics: Monitor API usage trends to optimise pricing and infrastructure.
Future Monetisation Models:
- Introduce pay-as-you-go pricing for smaller customers who need occasional data access.
- Offer custom analytics packages for large enterprises, bundling behavioural models with enriched data streams.
6. Scalability and Future Proofing
Horizontal Scaling:
- IoT Core: Scale with additional device endpoints as needed.
- Kinesis: Increase shard count dynamically based on ingestion volume.
Cloud-Native Tools:
- Use AWS Autoscaling to manage infrastructure elasticity.
- Migrate to containerised services (e.g., ECS or EKS) for workload flexibility.
Global Reach:
- Use AWS Global Accelerator to improve API response times for international customers.
- Implement multi-region replication in S3 for disaster recovery.
Future Roadmap
Year 1: MVP Development
- Deliver an MVP that ingests, enriches, and stores IoT data.
- Provide basic APIs for data access and introduce subscription-based monetisation.
Year 2: Scaling and AI Integration
- Add behavioural analytics and advanced AI models using SageMaker.
- Scale ingestion and processing pipelines to handle increased data volume.
- Expand monetisation with new pricing tiers and value-added features.
Year 3: Full Enterprise Platform
- Offer a complete governance solution with Lake Formation and DataBrew.
- Introduce marketplace integrations via AWS Data Exchange.
- Pursue international expansion with multi-region support and compliance.
Projected Benefits
- Scalability: Built on AWS, the platform grows seamlessly with IoT device adoption.
- Revenue Potential: Flexible monetisation models cater to diverse industries, from healthcare to retail.
- Customer Retention: Advanced analytics and behavioural insights drive long-term value.
- Compliance Assurance: Robust governance ensures alignment with GDPR, HIPAA, and other regulations.
This enhanced and streamlined roadmap provides a clear path for SAT Tech to establish itself as a leader in IoT data platforms, delivering value to customers while ensuring technical excellence and operational efficiency. By focusing on MVP delivery, scalability, and monetisation, SAT Tech can achieve long-term success in this competitive landscape.
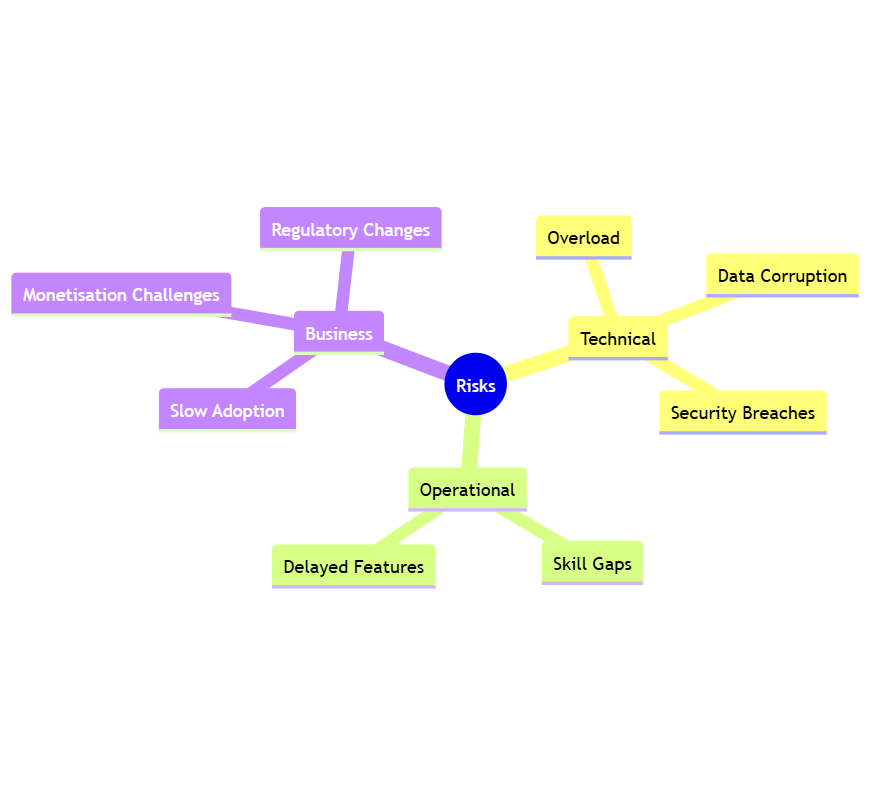
Key Risks and Mitigation Strategies
While the proposed platform offers a robust and scalable solution, it’s essential to identify potential risks and implement strategies to mitigate them. Below is a breakdown of risks across technical, operational, and business domains.
1. Technical Risks
Risk: High Ingestion Volume Overload
- Description: Unexpected spikes in IoT device data may overwhelm the ingestion layer, leading to data loss or pipeline delays.
- Mitigation Strategies:
- Implement Kinesis Enhanced Fan-Out to ensure high throughput.
- Use AWS Auto Scaling to dynamically adjust infrastructure based on traffic patterns.
- Build a fallback mechanism where data is temporarily stored in a DynamoDB stream if ingestion services are overloaded.
Risk: Data Corruption During Processing
- Description: Errors in enrichment or transformation workflows may lead to corrupted or unusable data.
- Mitigation Strategies:
- Include validation layers in Lambda and Glue to check data integrity at each step.
- Implement data versioning in S3 to allow rollback to previous states in case of corruption.
- Use AWS Step Functions for checkpointing during complex workflows.
Risk: Security Breaches
- Description: IoT data is sensitive, and any breach could result in regulatory penalties and reputational damage.
- Mitigation Strategies:
- Enforce end-to-end encryption for all data in transit and at rest.
- Regularly audit IAM policies to ensure least-privilege access.
- Conduct penetration testing and vulnerability assessments using tools like AWS Inspector.
Risk: Latency in Real-Time Analytics
- Description: Real-time APIs or dashboards may experience latency if data processing layers are overwhelmed.
- Mitigation Strategies:
- Use SageMaker Edge for lightweight model inference at the edge for time-sensitive analytics.
- Cache frequently accessed data in AWS ElastiCache (Redis or Memcached).
2. Operational Risks
Risk: Team Skill Gaps
- Description: Advanced AWS services and machine learning tools require specialised expertise, which may be unavailable.
- Mitigation Strategies:
- Allocate a training budget for certifications like AWS Certified Solutions Architect and Certified Machine Learning Specialist.
- Partner with AWS consulting teams during the initial setup.
- Employ managed services (e.g., AWS Glue Studio) to reduce operational complexity.
Risk: Delayed Feature Delivery
- Description: Complex features like AI/ML models or governance mechanisms may delay rollout.
- Mitigation Strategies:
- Adopt Agile methodology to deliver features incrementally.
- Prioritise MVP delivery and defer non-critical components (e.g., advanced analytics) to future phases.
- Include buffer time in project timelines for unforeseen issues.
Risk: Vendor Lock-In
- Description: Heavy reliance on AWS may create challenges in switching to other platforms in the future.
- Mitigation Strategies:
- Use open standards (e.g., Apache Parquet for data storage, Kubernetes for containers) where possible.
- Maintain a cloud-agnostic architecture for critical components.
- Periodically evaluate other cloud providers for cost and feature comparison.
3. Business Risks
Risk: Slow Customer Adoption
- Description: New customers may hesitate to adopt the platform, limiting early revenue generation.
- Mitigation Strategies:
- Target niche markets like healthcare and smart buildings for focused initial efforts.
- Offer free trials or discounted pricing tiers to attract early adopters.
- Highlight case studies and ROI metrics to demonstrate value.
Risk: Monetisation Challenges
- Description: Misaligned pricing models may deter smaller customers or limit high-value enterprise engagements.
- Mitigation Strategies:
- Conduct customer interviews and market research to validate pricing structures.
- Provide flexible options (e.g., pay-per-use, custom enterprise contracts).
- Use analytics to identify and adjust underperforming monetisation strategies.
Risk: Regulatory Changes
- Description: Changes in data privacy laws or regulations may require costly modifications to the platform.
- Mitigation Strategies:
- Stay updated on relevant regulations (e.g., GDPR, HIPAA, CCPA).
- Employ a Data Privacy Officer to oversee compliance workflows.
- Design workflows with configurability to adapt to new requirements (e.g., flexible anonymisation rules in Macie).
Scalability Roadmap
As the platform grows, its scalability must evolve to support larger customer bases, higher data volumes, and more complex analytics. Below are the key milestones for long-term scalability:
Year 1–2: Regional Scalability
- Expand Infrastructure: Add regional S3 buckets and IoT Core endpoints to improve performance in high-traffic areas.
- Optimise Data Pipelines: Migrate enrichment tasks to AWS Glue for more efficient processing.
- Customer Growth: Target healthcare, behavioural science, and smart building markets.
Year 3–4: Global Expansion
- Multi-Region Deployment: Enable cross-region replication for disaster recovery and compliance with data residency laws.
- Introduce Advanced Features: Add multilingual support and region-specific compliance tools for international customers.
- Diversify Monetisation: Expand into new industries (e.g., automotive, transportation) with tailored solutions.
Year 5+: AI-Driven Optimisation
- Predictive Analytics at Scale: Deploy global behavioural models using SageMaker and Deep Learning AMIs.
- Automated Platform Management: Use AI/ML to predict platform scaling needs and optimise costs dynamically.
- Full Ecosystem Integration: Partner with third-party marketplaces like AWS Data Exchange and enterprise SaaS platforms for seamless data integration.
Customer Success Stories (Future Vision)
Case Study 1: Healthcare Provider
- Challenge: Monitoring fall risks for elderly patients in home care.
- Solution: Used real-time motion data to detect anomalies and alert caregivers instantly.
- Outcome: Reduced fall-related incidents by 25%, improving patient safety and lowering costs.
Case Study 2: Smart Building Operator
- Challenge: Optimising energy usage across multiple high-traffic office buildings.
- Solution: Analysed motion data to adjust HVAC and lighting dynamically.
- Outcome: Achieved 15% energy savings annually while enhancing occupant comfort.
Case Study 3: Retail Chain
- Challenge: Understanding in-store customer behaviour to optimise product placement.
- Solution: Leveraged anonymised foot traffic data to redesign store layouts.
- Outcome: Increased sales by 10% within six months of implementation.
Conclusion
The SAT Tech IoT Data Lake Platform represents a robust, scalable, and secure solution for managing and monetising IoT data. By focusing on a phased implementation approach, the platform can deliver immediate value with an MVP while building towards advanced analytics, global scalability, and diverse monetisation models.
With a clear roadmap, risk mitigation strategies, and a focus on customer-centric use cases, SAT Tech is well-positioned to become a leader in IoT-driven insights, enabling innovation across industries while maintaining a strong commitment to data privacy and security.